
This is a work in progess document about things I consider interesting about http(s).
The Hypertext Transfer Protocol (HTTP) is based on TCP. Each HTTP request consists of a request and a response, both of them containing headers.
Notable request methods are: GET, POST, OPTIONS, HEAD, PUT, DELETE, UPDATE.
The following headers are allowed: https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers
The response has headers, possibly a body and always a return status code. Here are the allowed status codes: https://developer.mozilla.org/en-US/docs/Web/HTTP/Status
The answer looks like this:
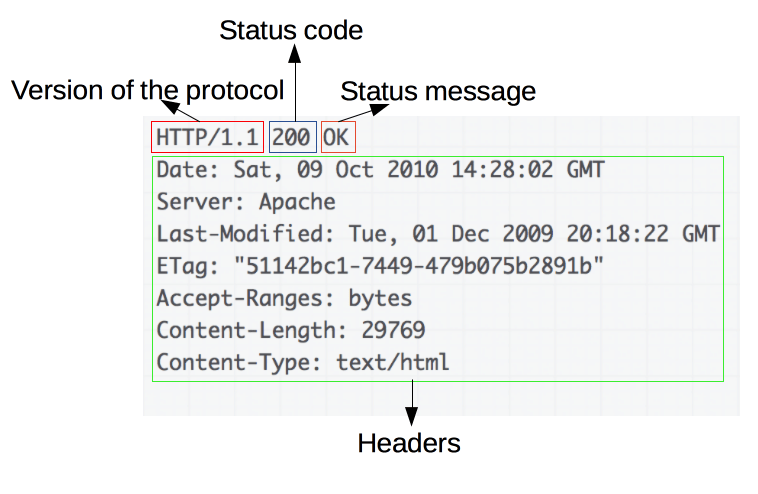
A good overview can be found at https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview
Chunked encoding
This is a tricky corner-case of http, where we don’t strictly follow the paradigm of one request one response. Instead when the participant sets the header Transfer-Encoding: Chunked and doesn’t set Content-Length header.
This means we transfer
A\r\n (number of octets in the chunk in hexadecimal)
TheContent (10 octets)
\r\n (chunk end)To indicate the end of stream we say
0\r\n (number of octets in the chunk in hexadecimal)
\r\n (chunk end)Curl
To make a curl request here is an example:
curl --trace-ascii - \
216.58.206.46 \
--request POST \
--header 'Accept:' \
--header 'User-Agent:' \
--header 'Host: google.com' \
--data 'mysuperdata'Web Crawlers and User Agents
User agents tell the servers who is requesting their page. User agents are generally a mess, because it was never intended that pages change their layout based on useragents or serve different javascript/css based on it.
Web crawlers look at the /robots.txt of every webserver before crawling it. Additionally most of them set their user-agent to tell the server that the served content is interpretet by a crawler.
Google uses the following user-agent for their crawlers:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/W.X.Y.Z Safari/537.36Note: Replace W X Y and Z with a valid IP.